# Broker 源码分析
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
Broker模块涉及到的内容非常多,以下技术点作为本篇文章的重点讲解:
1、Broker启动流程分析
2、消息存储设计
3、消息写入流程
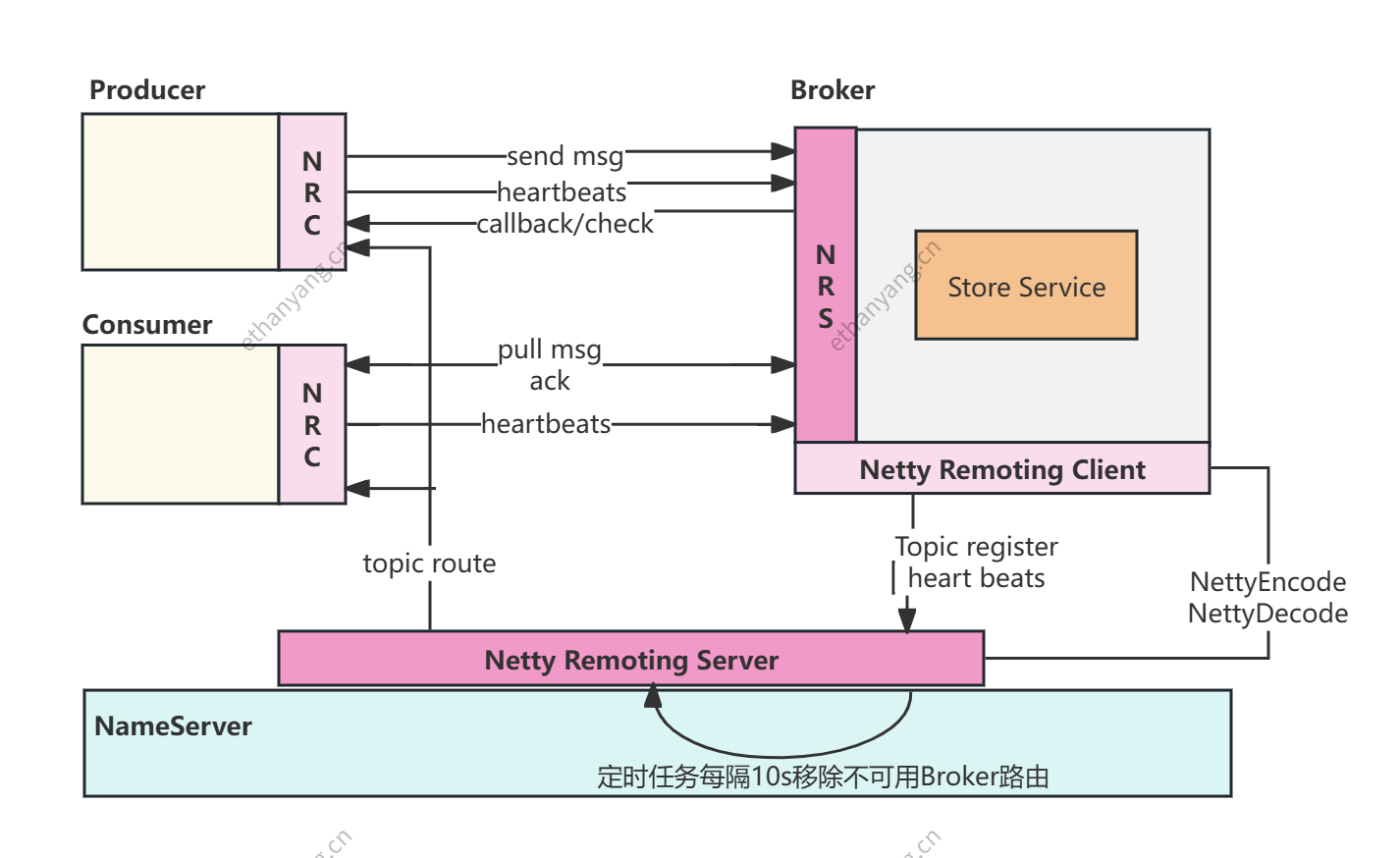
4、亮点分析:NRS与NRC的功能号设计
5、亮点分析:同步双写数倍性能提升的CompletableFuture
6、亮点分析:Commitlog写入时使用可重入锁还是自旋锁?
7、亮点分析:零拷贝技术之MMAP提升文件读写性能
8、亮点分析:堆外内存机制
# 1. Broker 启动流程分析
Broker 是 RocketMQ 中处理最密集的模块,因此启动流程理解非常关键。
核心启动流程如下: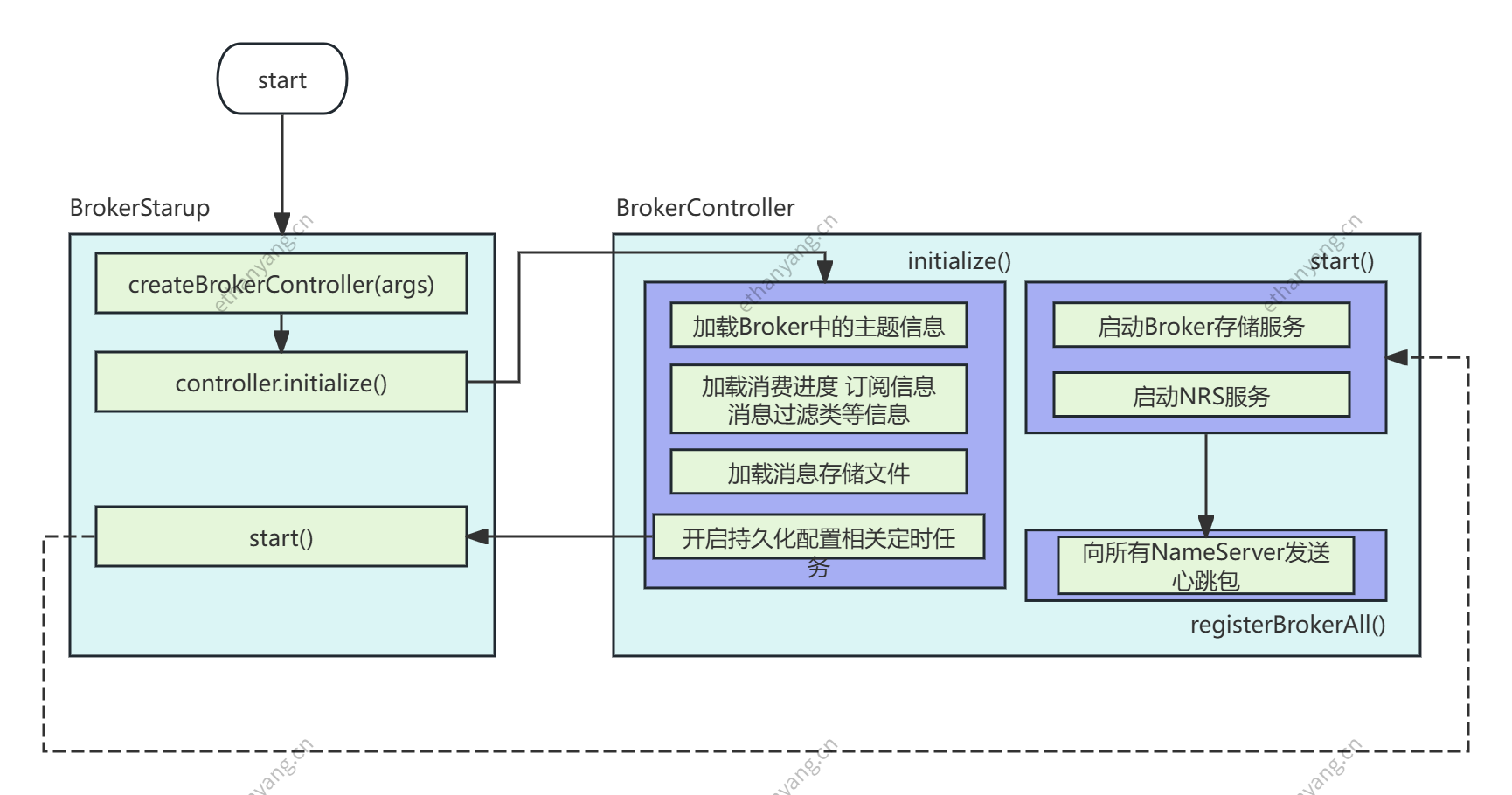
public class BrokerStartup {
public static Properties properties = null;
public static CommandLine commandLine = null;
public static String configFile = null;
public static InternalLogger log;
public static void main(String[] args) {
//todo 有两步,一个 create, 一个start
start(createBrokerController(args));
}
}
public static BrokerController createBrokerController(String[] args) {
// .... 省略
final BrokerController controller = new BrokerController(
brokerConfig,
nettyServerConfig,
nettyClientConfig,
messageStoreConfig);
// remember all configs to prevent discard
controller.getConfiguration().registerConfig(properties);
//初始化
boolean initResult = controller.initialize();
// .... 省略
}
public boolean initialize() throws CloneNotSupportedException {
//todo 加载Broker中的主题信息 json
boolean result = this.topicConfigManager.load();
//todo 加载消费进度
result = result && this.consumerOffsetManager.load();
//todo 加载订阅信息
result = result && this.subscriptionGroupManager.load();
//todo 加载订消费者过滤信息
result = result && this.consumerFilterManager.load();
// .... 省略
}
public static BrokerController start(BrokerController controller) {
// .... 省略
controller.start();
// .... 省略
}
public void start() throws Exception {
//启动消息存储组件
if (this.messageStore != null) {
this.messageStore.start();
}
//启动netty服务器
if (this.remotingServer != null) {
this.remotingServer.start();
}
// .... 省略
// broker每隔30s向NameServer发送心跳包
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
//todo 向NameServer发送心跳包
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
log.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 2. 消息存储设计
Kafka 的文件布局以 Topic/Partition 为基本单位。每个分区对应一个独立目录,消息在分区内顺序写入。随着 Topic 和 Partition 数量增多,Broker 上的分区文件数量随之增长,消息写入会变得更加分散,最终使磁盘 IO 在大量分区中竞争,从高度顺序写退化为“伪随机写”。这会影响整体写入稳定性,尤其是在主题数量和消费者数量非常多的业务场景中。
RocketMQ 的设计完全不同:
- 所有 Topic 的消息都顺序写入同一个 CommitLog 文件
- 消费逻辑通过 ConsumeQueue 索引提供
- 消息写入始终保持严格的顺序写,无论 Topic 有多少
RocketMQ 在多 Topic、多消费者、高并发业务场景下,仍能保持消息一致性、顺序性和写入稳定性。 Kafka 更强调分区级别的吞吐扩展性,但顺序性和一致性容易受到分区策略影响。
# 3. 存储文件设计
RocketMQ 的存储体系由三类核心文件构成:CommitLog、ConsumeQueue、IndexFile。 这三类文件共同支撑了 RocketMQ 的高吞吐顺序写、顺序消费、高效定位等核心能力:
- CommitLog:消息物理存储(所有消息统一顺序写入)
- ConsumeQueue:消费索引(按 Topic/Queue 构建固定长度顺序索引)
- IndexFile:Key 查询索引(按 key 或 uniqKey 快速定位消息)
RocketMQ 通过 “物理日志 + 逻辑队列 + 辅助索引” 的分层设计,实现了:
- 写入时极致顺序写性能
- 消费时按 MessageQueue 顺序读取
- 运维和查询场景下通过 Key/时间快速检索消息
# 3.1 存储目录结构概览
CommitLog 与 ConsumeQueue 的存储结构如下图所示(省略部分):
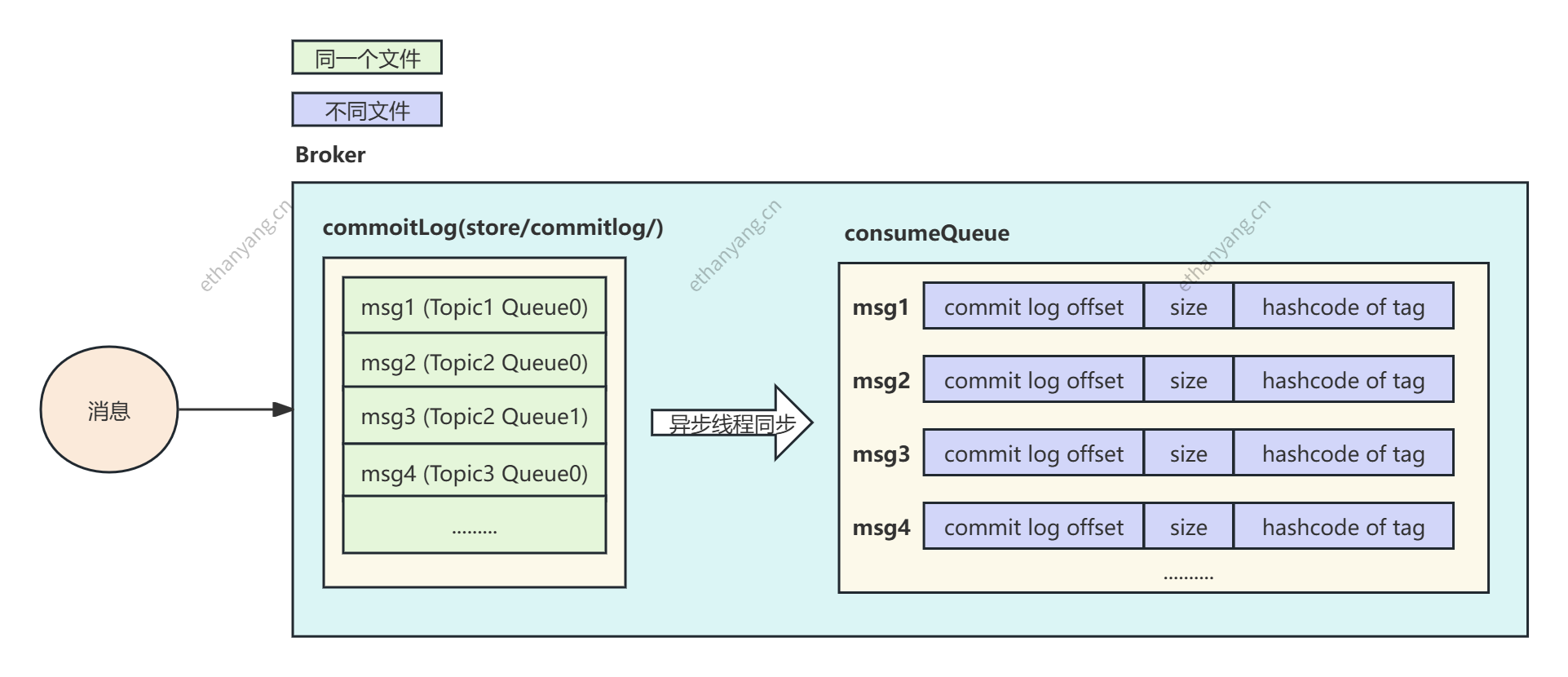
对应的真实文件目录结构如下:
store/
├── commitlog/
│ ├── 00000000000000000000 // CommitLog 按 1GB 滚动切分,文件名为起始偏移量
│ ├── 00000001073741824000
│ └── ...
├── consumequeue/
│ ├── Topic1/
│ │ ├── 0/ // Topic1 的 Queue0
│ │ │ ├── 00000000000000000000 // ConsumeQueue 以 Queue 为粒度拆分
│ │ │ ├── 00000000000000524288 // 文件名为该文件的起始逻辑 offset * 20B
│ │ │ └── ...
│ ├── Topic2/
│ │ ├── 0/
│ │ ├── 1/
│ │ └── ...
├── index/
│ ├── 202404021300.index
│ └── ...
└── config/
├── topics.json
├── subscriptionGroup.json
├── delayOffset.json
├── consumerOffset.json
└── ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3.2 三类文件的作用与定位
# 1) CommitLog
- RocketMQ 所有 Topic、所有 Queue 的真实消息,全部写入统一的 CommitLog
- 文件为 顺序追加(Append-Only)
- 每条消息可变长
- 按 1GB 自动切分(由
mappedFileSizeCommitLog控制) - 多个物理文件构成一个逻辑连续的 CommitLog
顺序写磁盘性能远高于随机写(NVMe 顺序写可达数百 MB/s),这也是 RocketMQ 整体高吞吐的基础。
# 2) ConsumeQueue
ConsumeQueue 是 每个 Topic/Queue 的独立逻辑队列,其作用是让消费者无需扫描 CommitLog,而是:
“通过固定长度索引顺序读取消息”。
每条索引记录固定为 20 字节:
| 字段 | 大小 | 说明 |
|---|---|---|
| commitLogOffset | 8B | 指向 CommitLog 内消息物理位置 |
| msgSize | 4B | 消息大小(便于跳转) |
| tagHashCode | 8B | Tag 过滤加速(Push 模式) |
ConsumeQueue 文件结构特点:
- 以 Queue 粒度拆分文件(Queue0、Queue1…)
- 每个 ConsumeQueue 文件固定大小约 5MB
- 写满后自动滚动产生新文件(多个文件构成逻辑队列)
- 读取时直接 mmap 至内存,顺序扫描性能极高
消费流程一定是通过 ConsumeQueue 索引 → CommitLog,不会跳过 ConsumeQueue。
# 3) IndexFile
IndexFile 是用于 非顺序查询 的可选结构,主要用于:
- 按 messageKey 或 uniqKey 查询消息
- 事务消息回查
- 按时间戳查消息
- 运维场景(查找 DLQ、恢复消息等)
其结构为典型的 Hash Slot + 冲突链表:
- HashSlot 数组:存储链表入口
- IndexItems:链式存储 commitLogOffset 与时间戳
IndexFile 提供高效查询能力,但不参与顺序消费。
# 3.3 CommitLog 与 ConsumeQueue 的存储结构
# CommitLog
逻辑上:
- 一个无限增长的顺序日志文件
物理上:
- 由多个固定大小(默认 1GB)的 MappedFile 组成
- 多文件构成一个逻辑连续地址空间
- 文件名 = 起始偏移量(20 位数字)
示例:
00000000000000000000 // offset = 0
00000001073741824000 // offset = 1GB
00000002147483648000 // offset = 2GB
2
3
Broker 统一向末尾 append,新文件按需创建。
# ConsumeQueue
逻辑上:
- 每个 Topic 下的每个 Queue 是一个独立的逻辑队列
- 每个 Queue 有自己的 offset 0、offset 1…
物理上:
- 以 Queue 为粒度生成目录
- 每个 Queue 目录内存放多个固定大小的 ConsumeQueue 文件(~5MB)
- 文件名 = 起始 index * 20 字节
示例:
00000000000000000000 // 从逻辑 offset = 0 开始
00000000000000524288 // 从逻辑 offset = 262144 开始
2
ConsumeQueue 的“固定长度 + 多文件分块”模式,保证了:
- O(1) 的消息定位能力
- 顺序消费的高性能
- 快速恢复与快速删除(文件分段)
- mmap 友好,减少 PageCache 压力
# 3.4 消息存储结构源码对应
public boolean initialize() throws CloneNotSupportedException {
//todo 加载Broker中的主题信息 json
boolean result = this.topicConfigManager.load();
//todo 加载消费进度
result = result && this.consumerOffsetManager.load();
//todo 加载订阅信息
result = result && this.subscriptionGroupManager.load();
//todo 加载订消费者过滤信息
result = result && this.consumerFilterManager.load();
.... 省略
result = result && this.messageStore.load();
}
public boolean load() {
boolean result = true;
try {
boolean lastExitOK = !this.isTempFileExist();
log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");
if (null != scheduleMessageService) {
result = result && this.scheduleMessageService.load();
}
// load Commit Log(零拷贝技术)
result = result && this.commitLog.load();
// load Consume Queue(零拷贝技术)
result = result && this.loadConsumeQueue();
// 省略 ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 4 消息写入流程
Producer 发送消息到 Broker 后,Broker 内部会经过 网络层 → 存储逻辑层 → 存储 I/O 层 三个阶段,最终把消息写入 CommitLog,并由后台线程异步构建 ConsumeQueue。
整体流程如下图所示(逻辑层视角):
Netty → SendMessageProcessor → DefaultMessageStore → CommitLog → MappedFile(page cache) → Flush → ReputMessageService(构建 CQ / Index)
下面分层介绍整条写入链路。
# 4.1 网络层:SendMessageProcessor 接收并处理请求
Broker 使用 Netty 接收客户端请求,发送消息的请求交给 SendMessageProcessor.processRequest 处理:
public RemotingCommand processRequest(ChannelHandlerContext ctx,
RemotingCommand request) {
return asyncProcessRequest(ctx, request).get();
}
2
3
4
这里虽然使用的是 asyncProcessRequest,但最终调用 .get() 阻塞等待结果,是 同步返回。
Future 只是统一接口风格,方便后续扩展真正异步处理。
# 4.2 存储入口:DefaultMessageStore.asyncPutMessage
DefaultMessageStore 是存储层统一入口,负责:
- 检查 Broker 是否可写
- 检查消息是否合法
- 分发到 CommitLog 执行真正写入
核心逻辑:
public CompletableFuture<PutMessageResult> asyncPutMessage(MessageExtBrokerInner msg) {
// 1. Broker 存储状态检查
checkStoreStatus();
// 2. 消息本身合法性检查
checkMessage(msg);
// 3. 进入 CommitLog 执行消息写入
return commitLog.asyncPutMessage(msg);
}
2
3
4
5
6
7
8
# 4.3 存储 I/O 层:CommitLog 写入消息
CommitLog.asyncPutMessage 是写入消息的核心过程,它承担了:
- 设置存储时间、CRC 校验
- 延时消息处理
- 获取或创建 CommitLog 文件
- 加锁保证顺序写
- 写入 MappedFile 内存(page cache)
- 调用刷盘/复制服务
核心代码片段:
public CompletableFuture<PutMessageResult> asyncPutMessage(MessageExtBrokerInner msg) {
msg.setStoreTimestamp(System.currentTimeMillis());
msg.setBodyCRC(UtilAll.crc32(msg.getBody()));
// 延时消息 topic 变化处理
if (msg.getDelayTimeLevel() > 0) {
msg.setTopic(SCHEDULE_TOPIC);
msg.setQueueId(delayLevel2QueueId(msg.getDelayTimeLevel()));
...
}
// 获取最新的 MappedFile
MappedFile mappedFile = mappedFileQueue.getLastMappedFile();
putMessageLock.lock();
try {
// 文件满了则创建新文件
if (mappedFile == null || mappedFile.isFull()) {
mappedFile = mappedFileQueue.getLastMappedFile(0);
}
// 写入 PageCache(并没有立即刷盘)
AppendMessageResult result = mappedFile.appendMessage(msg, appendMessageCallback);
// ... 调用刷盘服务、复制服务
} finally {
putMessageLock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 关键点:CommitLog 写入只是“写 page cache”,不等于磁盘落盘
真正的刷盘由专门的 Flush 服务完成(同步/异步刷盘),并由复制服务推动主从复制。
# 4.4 异步生成 ConsumeQueue:ReputMessageService
连续发送5条消息,消息是不定长,首先所有信息先放入 Commitlog中,每一条消息放入 Commitlog 的时候都需要上锁,确保顺序的写入。
当Commitlog写成功了之后。数据通过ReputMessageService类定时同步到ConsumeQueue中,写入Consume Queue的内容是定长的,固定是20个Bytes(offset 8个、size 4个、Hashcode of Tag 8个)。
这种设计非常的巧妙:
查找消息的时候,可以直按根据队列的消息序号,计算出索引的全局位置(比如序号2,就知道偏移量是20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。这两次查找是差不多的:第一次在通过序号在consumer Queue中获取数据的时间复杂度是O(1),第二次查找commitlog文件的时间复杂度也是O(1),所以消费时查找数据的时间复杂度也是O(1)。
RocketMQ 的设计是:
CommitLog 是消息的唯一存储。 ConsumeQueue / Index 是由独立线程从 CommitLog 回放(Reput)得到的“派生结构”。
后台线程:ReputMessageService
class ReputMessageService extends ServiceThread {
@Override
public void run() {
while (!isStopped()) {
doReput(); // 不断重放 CommitLog
}
}
}
2
3
4
5
6
7
8
# doReput 的核心逻辑:
private void doReput() {
while (reputFromOffset < commitLog.getMaxOffset()) {
// 1. 从 CommitLog 读取一条消息
SelectMappedBufferResult data = commitLog.getData(reputFromOffset);
// 2. 解析为 DispatchRequest
DispatchRequest req = messageDecoder.decode(data);
// 3. 分发给多个 Dispatcher
doDispatch(req); // ConsumeQueue / Index 均在此构建
// 4. 更新偏移
reputFromOffset += req.getMsgSize();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
其中:
- CommitLogDispatcherBuildConsumeQueue:负责写入 ConsumeQueue
- CommitLogDispatcherBuildIndex:负责构建 IndexFile
# 总结一句话:
CommitLog 写入成功后,并不会立即生成 ConsumeQueue,而是由
ReputMessageService后台线程异步构建,通常有几十毫秒到几百毫秒的延迟(dispatch lag)。
# 4.5 RocketMQ 写入流程总结图
下面是简化版完整链路:
Producer
↓(发送消息)
Netty Server
↓(解析请求)
SendMessageProcessor
↓
DefaultMessageStore.asyncPutMessage
↓
CommitLog.asyncPutMessage
↓(加锁顺序写入)
MappedFile.appendMessage ← 写入 page cache(未刷盘)
↓
(FlushService 异步/同步刷盘)
↓
(HAService 复制到 Slave)
【后台异步】
ReputMessageService
↓(从 CommitLog 回放消息)
CommitLogDispatcherBuildConsumeQueue
↓
更新 ConsumeQueue(逻辑队列)
CommitLogDispatcherBuildIndex
↓
更新 IndexFile
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
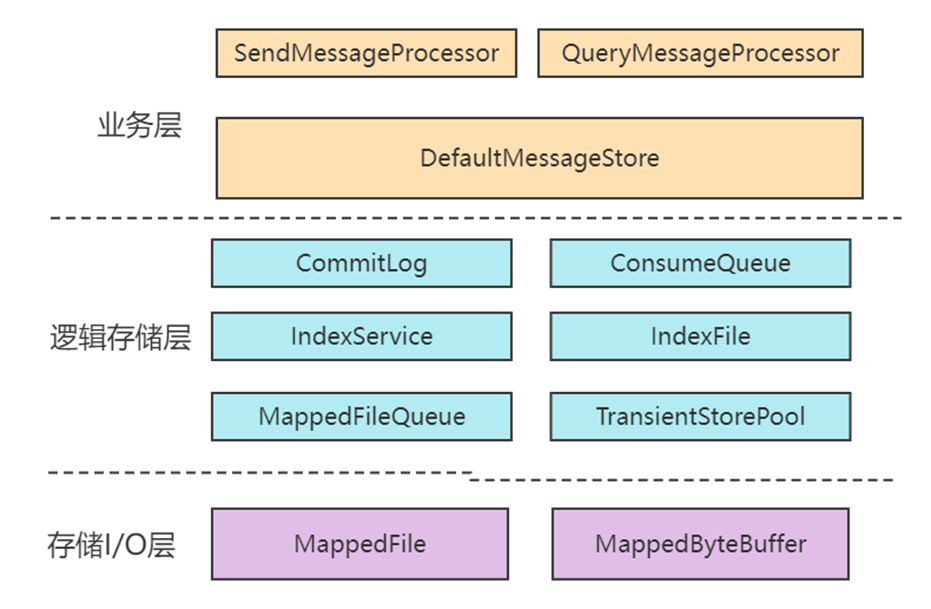
整个存储体系就三层:
- 业务层(网络层):负责接收和分发请求
- 存储逻辑层:DefaultMessageStore、CommitLog、ConsumeQueue 等
- 存储 I/O 层:MappedFile(mmap)、Flush、HA
# 4.6 为什么 RocketMQ 要异步生成 ConsumeQueue?
这是 RocketMQ 高性能的核心原因:
| 方案 | 消息写入延迟 | 吞吐量 |
|---|---|---|
| 写 CommitLog + 同步生成 CQ | 高 | 低 |
| 写 CommitLog + 异步生成 CQ(RocketMQ) | 低 | 高 |
原因:
- CommitLog 是顺序写,非常快
- ConsumeQueue 写入比较随机、开销更大
- 解耦后,消息写入路径最短、延迟最低
- 消费进度和实际消息读取最终一致即可(CQ 可以重建)
整个存储设计层次非常清晰,大致的层次如下图:
# 5 源码分析中亮点
# 5.1 同步双写数倍性能提升的CompletableFuture
在RocketMQ4.7.0之后,RocketMQ大量使用Java中的异步编程接口CompletableFuture。尤其是在Broker端进行消息接收处理时。
比如:DefaultMessageStore类中asyncPutMessage方法
public CompletableFuture<PutMessageResult> asyncPutMessage(MessageExtBrokerInner msg) {
PutMessageStatus checkStoreStatus = this.checkStoreStatus();
if (checkStoreStatus != PutMessageStatus.PUT_OK) {
return CompletableFuture.completedFuture(new PutMessageResult(checkStoreStatus, null));
}
PutMessageStatus msgCheckStatus = this.checkMessage(msg);
if (msgCheckStatus == PutMessageStatus.MESSAGE_ILLEGAL) {
return CompletableFuture.completedFuture(new PutMessageResult(msgCheckStatus, null));
}
long beginTime = this.getSystemClock().now();
//这里会进入commitLog的消息处理逻辑
CompletableFuture<PutMessageResult> putResultFuture = this.commitLog.asyncPutMessage(msg);
2
3
4
5
6
7
8
9
10
11
12
13
14
Future接口正是设计模式中Future模式的一种实现:如果一个请求或任务比较耗时,可以将方法调用改为异步,方法立即返回,任务则使用主线程外的其他线程异步执行,主线程继续执行。当需要获取计算结果时,再去获取数据。
在Master-Slave主从架构下,Master 节点与 Slave 节点之间数据同步/复制的方式有同步双写和异步复制两种模式。同步双写是指Master将消息成功落盘后,需要等待Slave节点复制成功(如果有多个Slave,成功复制一个就可以)后,再告诉客户端消息发送成功。
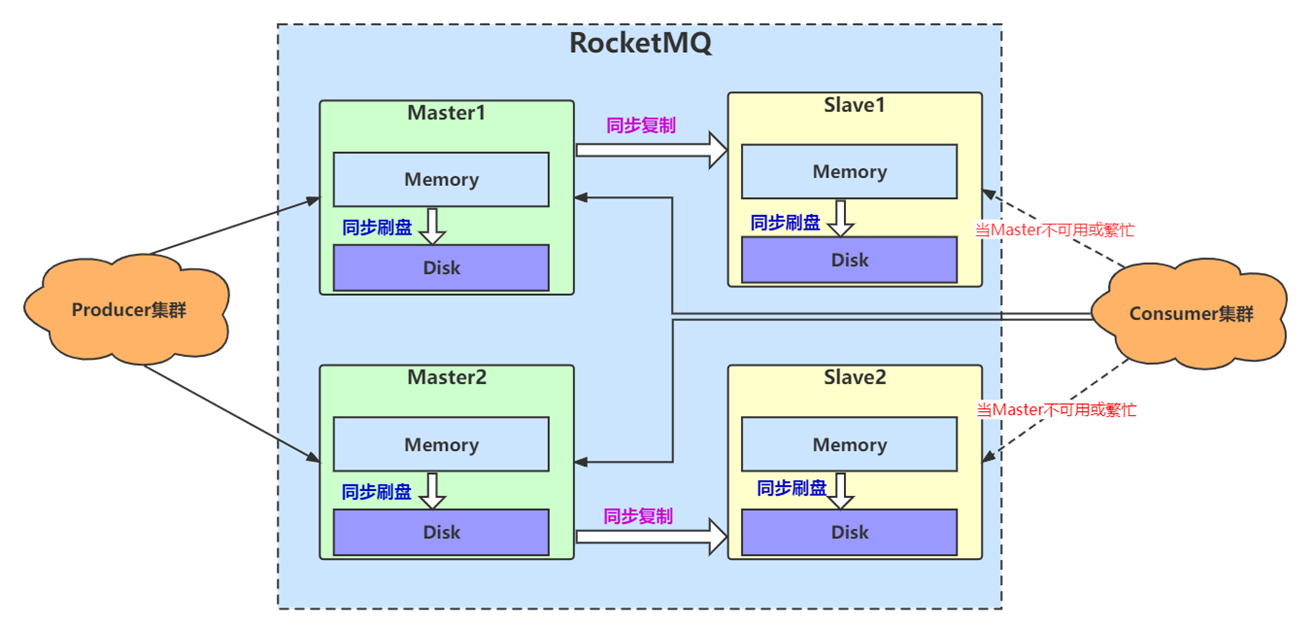
RocketMQ 4.7.0 以后合理使用CompletableFuture对同步双写进行性能优化,使得对消息的处理流式化,大大提高了Broker的接收消息的处理能力。
# ⭐5.2 Commitlog 写入时使用可重入锁还是自旋锁?
RocketMQ 在写入 CommitLog 时会使用互斥锁保证“同一时刻只有一个线程写 CommitLog”。 为了兼容不同的刷盘策略(同步刷盘 / 异步刷盘),RocketMQ 提供了两种可选锁:
- 自旋锁(SpinLock)
- 可重入锁(ReentrantLock)
源码如下:
//todo putMessgae会有多个线程并行处理,需要上锁
putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
try {
long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();
this.beginTimeInLock = beginLockTimestamp;
... 省略 ....
elapsedTimeInLock = this.defaultMessageStore.getSystemClock().now() - beginLockTimestamp;
beginTimeInLock = 0;
} finally {
putMessageLock.unlock();//解锁:标准的lock锁的方式
}
2
3
4
5
6
7
8
9
10
11
12
RocketMQ 允许通过配置项动态切换:
useReentrantLockWhenPutMessage=false(默认使用自旋锁)
RocketMQ 官方文档优化建议:异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁
//useReentrantLockWhenPutMessage参数默认是false,使用自旋锁。异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁
this.putMessageLock = defaultMessageStore.getMessageStoreConfig().isUseReentrantLockWhenPutMessage() ?
new PutMessageReentrantLock() : new PutMessageSpinLock();
2
3
同步刷盘时,锁竞争激烈,会有较多的线程处于等待阻塞等待锁的状态,如果采用自旋锁会浪费很多的CPU时间,所以“同步刷盘建议使用重入锁”。
异步刷盘是间隔一定的时间刷一次盘,锁竞争不激烈,不会存在大量阻塞等待锁的线程,偶尔锁等待就自旋等待一下很短的时间,不要进行上下文切换了,所以采用自旋锁更合适。
# 5.3 零拷贝技术之MMAP提升文件读写性能
RocketMQ 对 CommitLog、ConsumeQueue 等文件的读写都采用了 MMAP(内存映射) 技术。
底层实现依赖 JDK NIO 的 MappedByteBuffer.map() 方法,将磁盘文件直接映射到用户空间。
# 1. 为什么需要 MMAP?(解决“多次拷贝”问题)
如果不使用 MMAP,传统的文件 I/O 流程如下:
磁盘 → 内核页缓存(Kernel Buffer) → 用户空间(User Buffer)
整个过程需要 两次数据拷贝:
- 磁盘 → 内核缓冲区
- 内核缓冲区 → 用户空间
这会消耗:
- CPU 拷贝开销
- 内存带宽
- 系统调用开销(read/write)
在高吞吐 MQ 场景下,这种方式成本太高。
# 2. MMAP 如何实现“零拷贝”?
MMAP 会将文件的一段区域直接“映射”为用户空间的一块内存:
磁盘文件 ↔ 映射到用户空间的虚拟地址
因此,读取数据时:
- 不需要从内核缓存复制到用户缓存
- CPU 不参与中间复制动作
- 应用可以像使用普通内存一样操作文件内容
实际 I/O 流程变为:
磁盘 → 用户空间映射区(仅一次拷贝)
减少一次拷贝,属于 零拷贝技术的一种实现方式。
RocketMQ 的 commitlog/consumequeue 写入,即通过直接写映射内存,写入 PageCache,后续刷盘由操作系统负责。
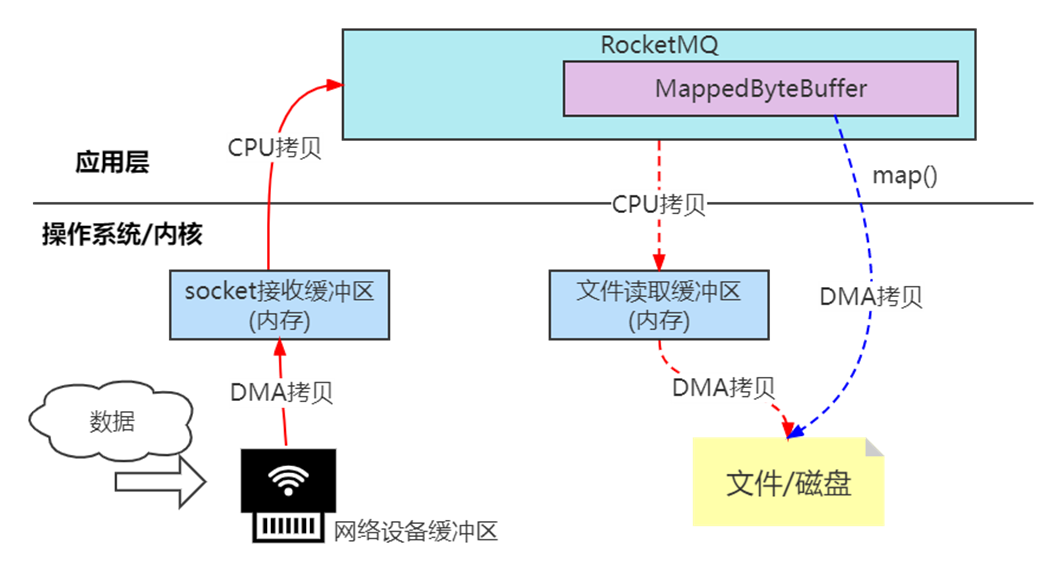
Broker启动时MMAP相关源码如下:
MappedFile类的init方法
private void init(final String fileName, final int fileSize) throws IOException {
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
// 核心:将文件映射到内存(mmap)
this.mappedByteBuffer =
this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
}
2
3
4
5
6
7
8
9
10
说明:
FileChannel.map()会创建一个 MappedByteBuffer- 该 buffer 指向文件在用户空间的映射区域
- 后续所有写入 CommitLog 的操作(appendMessage)都是对这段内存的直接写入
这意味着:
- 写 CommitLog 不需要系统调用 write()
- 写入仅为内存操作(写 PageCache)
- 刷盘由操作系统的 VM 机制异步完成(或由 RocketMQ 刷盘服务主动调用
force())
# 5.4 堆外内存机制
RocketMQ 在默认情况下通过 MMAP + PageCache 完成 CommitLog 的写入与读取; 除此之外,还提供了一种 堆外内存缓冲机制(TransientStorePool),用于进一步提升写入性能、减少 PageCache 竞争。
TransientStorePool 属于 短暂缓冲池(堆外内存),通过 DirectByteBuffer 直接分配内存,不占用 JVM Heap。
# 5.5.1 开启条件及限制
要启用堆外内存,需要在 broker 配置中开启:
transientStorePoolEnable = true
开启该机制的前提条件:
- 必须是异步刷盘(ASYNC_FLUSH) 因为堆外内存写入是“两段式写入”,同步刷盘会导致延迟非常大。
- Broker 必须为主节点(Master) Slave 节点不支持,因为 Slave 不负责写入 CommitLog。
DefaultMessageStore. DefaultMessageStore()
this.transientStorePool = new TransientStorePool(messageStoreConfig);
if (messageStoreConfig.isTransientStorePoolEnable()) {
this.transientStorePool.init(); // 初始化堆外内存池
}
2
3
4
# 5.5.2 堆外缓冲区流程
开启 TransientStorePool 后,写入 CommitLog 的流程从原来的:
Producer → PageCache(MMAP) → CommitLog 文件
变为“两层架构”:
Producer → DirectByteBuffer(堆外内存) → PageCache(MMAP) → CommitLog 文件
对应 RocketMQ 中的流程:
- 写消息先写入 DirectByteBuffer(堆外缓冲池)
- Commit 线程 定期将堆外数据拷贝到 MappedByteBuffer(即 PageCache)
- Flush 线程 将 PageCache 刷盘到磁盘文件
示意图如下:
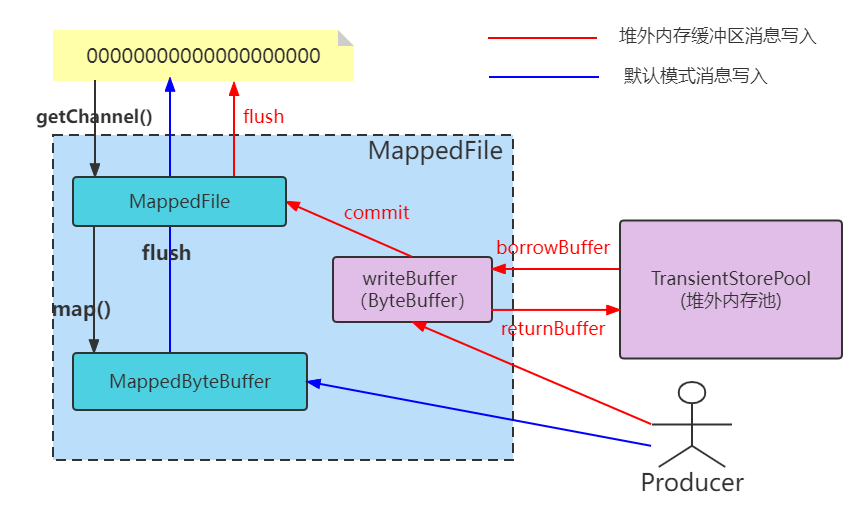
# 5.5.3 为什么要多这一层?
- DirectByteBuffer 位于 JVM 堆外,不会触发 GC
- 堆外内存可以通过 mlock 长期锁定在物理内存中,避免 swap
- 写入时不会直接污染 PageCache,使读写解耦,降低锁竞争